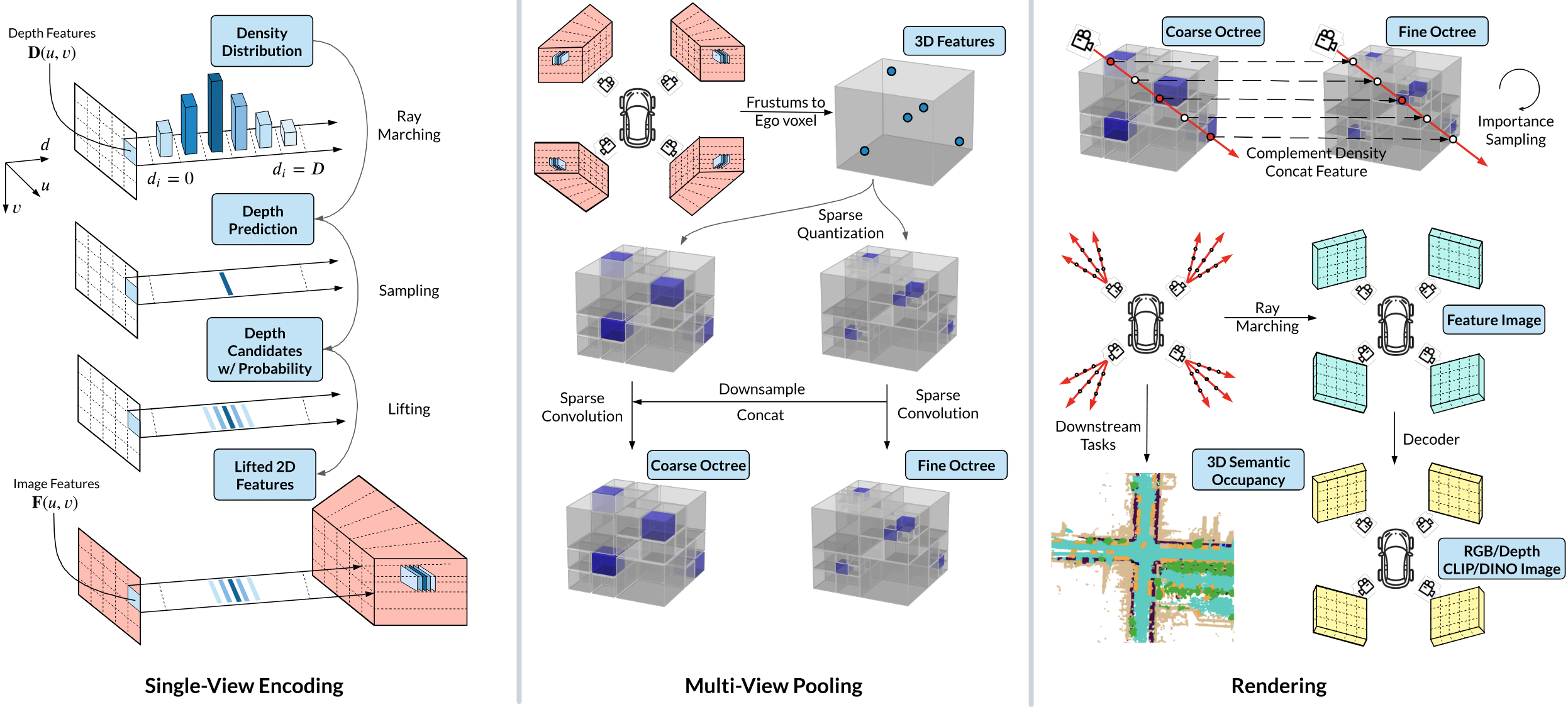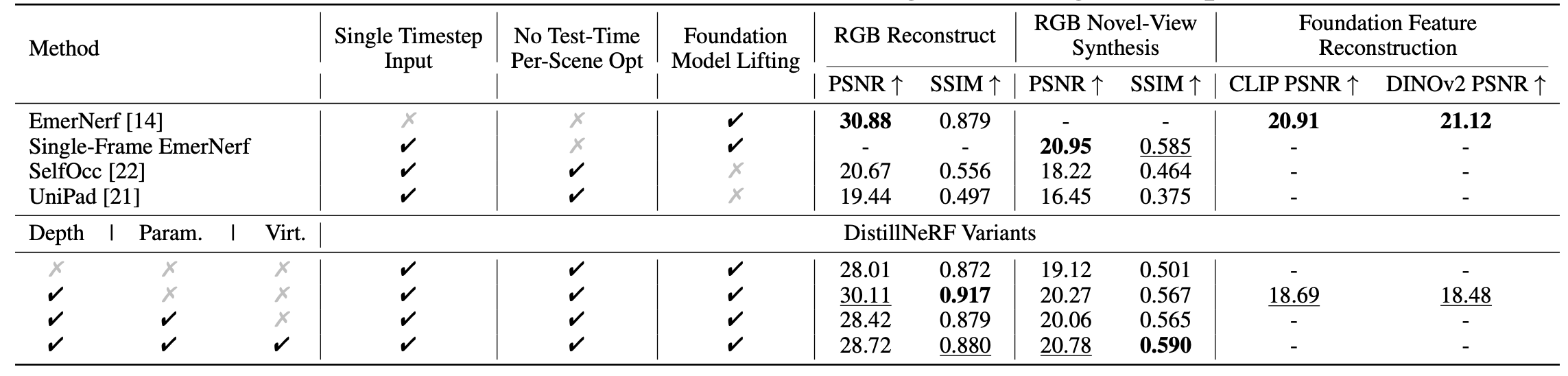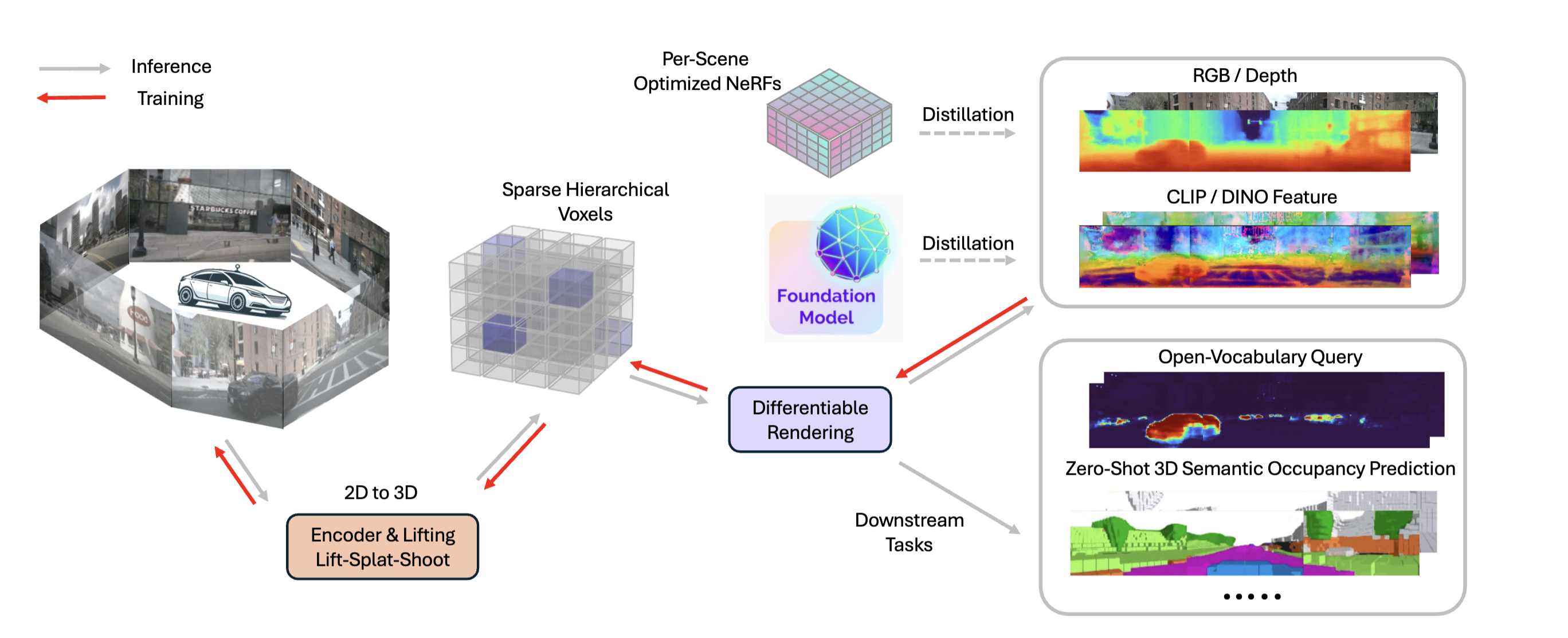
DistillNeRF is a generalizable model for 3D scene representation, self-supervised by natural sensor streams along with distillation from offline NeRFs and vision foundation models. It supports rendering RGB, depth, and foundation feature images, without test-time per-scene optimization, and enables downstream tasks such as zero-shot 3D semantic occupancy prediction and open-vocabulary text queries.